# Začneme iniciací prostředí.
library(tidyverse)
# pokud soubory neexistují lokálně - stahnout!
if (!file.exists('./data/potraviny.csv')) {
curl::curl_download("https://www.jla-data.net/sample/R4SU-potraviny.csv",
"./data/potraviny.csv")
}
# lokální soubor načíst
potraviny_csv <- readr::read_csv2("./data/potraviny.csv")Případová studie – cena piva v Praze a v čase
Cílem případovky bude zejména:
- procvičit manipulaci s daty: package
dplyra klíčová slovesafilter,mutateasummarise - procvičit vizualizaci dat: package
ggplot2a kreslení bodů a čar - sestavit a vyložit jednoduchý regresní model
Transformace dat
Manipulaci s daty začneme výpočtem průměrné roční ceny piva v Praze. Vybereme tedy cenového reprezentanta pivo a referenční území kraj Prahu. Období necháme bez omezení, ale seskupíme podle roku a vypočteme průměr.
Průměrná cena je složitější než se může zdát, protože ceny jsou vykázány za nestejně dlouhá období (interval mezi obdobiod a obdobido není vždy stejně dlouhý).
Nemůžeme proto uplatnit prostý průměr (funkci mean()) ale musíme napřed spočítat počet dní, po který cena platí, a pak použít vážený průměr (weighted.mean()), kdy vahou bude délka období platnosti ceny ve dnech.
pivo <- potraviny_csv %>% # vytvoříme objekt pivo tak, že vezmeme potraviny a pak ...
filter(reprcen_txt == "Pivo výčepní, světlé, lahvové [0,5 l]" # vybereme pivo ...
& uzemi_txt == "Hlavní město Praha") %>% # ... a Prahu, a pak...
mutate(rok = lubridate::year(obdobiod), # spočteme rok měření,
# a délku období pro které platí cena, a pak...
delka_obdobi = as.numeric(obdobido - obdobiod)) %>%
group_by(rok) %>% # podle roku měření seskupíme, a pak...
summarise(cena = weighted.mean(hodnota, delka_obdobi)) # spočteme průměrou cenuModel a předpověď
Druhým krokem je sestavení jednoduchého modelu lineární regrese funkcí lm() (zkratka pro linear model). Argumentem jsou použitá data (data =) a funkce s cenou podle roku (tilda – ~ má funkci “podle” = odděluje závislou proměnnou od nezávislých).
Hledáme tedy funkci, která by říkala že cena piva = β₀ + β₁ × rok, kde β₀ je konstanta a β₁ je koeficient.
model_piva <- lm(data = pivo, cena ~ rok) # lineární model - cena podle času
summary(model_piva) # shrnutí modelu##
## Call:
## lm(formula = cena ~ rok, data = pivo)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.20835 -0.07712 -0.01625 0.05287 0.32492
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -431.43563 22.01514 -19.60 6.65e-10 ***
## rok 0.21959 0.01094 20.07 5.15e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.1476 on 11 degrees of freedom
## Multiple R-squared: 0.9734, Adjusted R-squared: 0.971
## F-statistic: 402.8 on 1 and 11 DF, p-value: 5.151e-10Koeficient β₁ nám vyšel 0.2196, což si vyložíme tak, že cena univerzální normolahve piva v Praze se každým rokem zvedne o 21.96 haléřů.
Když jsme model sestavili, tak pomocí summary() zhodnotíme jeho vlastnosti. Zvláštní pozornost věnujeme koeficientu R² – hodnota 0.971 je dost dobrá.
Na základě minulosti připravíme pomocí funkce predict() odhad budoucnosti; argumentem new_data upřesníme na jaké období předpovídáme.
budoucnost <- predict(model_piva, # předpověď dle modelu ceny piva v Praze...
newdata = data.frame(rok = 2019:2023), # ... na pět let dopředu
level = .95, interval = "prediction") %>% # ... plus mínus 5%
as.data.frame() # jako data frame (a ne matice)
budoucnost## fit lwr upr
## 1 11.91547 11.53852 12.29243
## 2 12.13506 11.74674 12.52339
## 3 12.35465 11.95383 12.75547
## 4 12.57424 12.15990 12.98858
## 5 12.79383 12.36505 13.22262Předpověď děláme intervalovou, plus mínus 5% (tj. interval 0.95). Získáme tak kromě středové předpovědi (fit) také horní (upr) a dolní (lwr) hranici intervalu s 95% mírou konfidence.
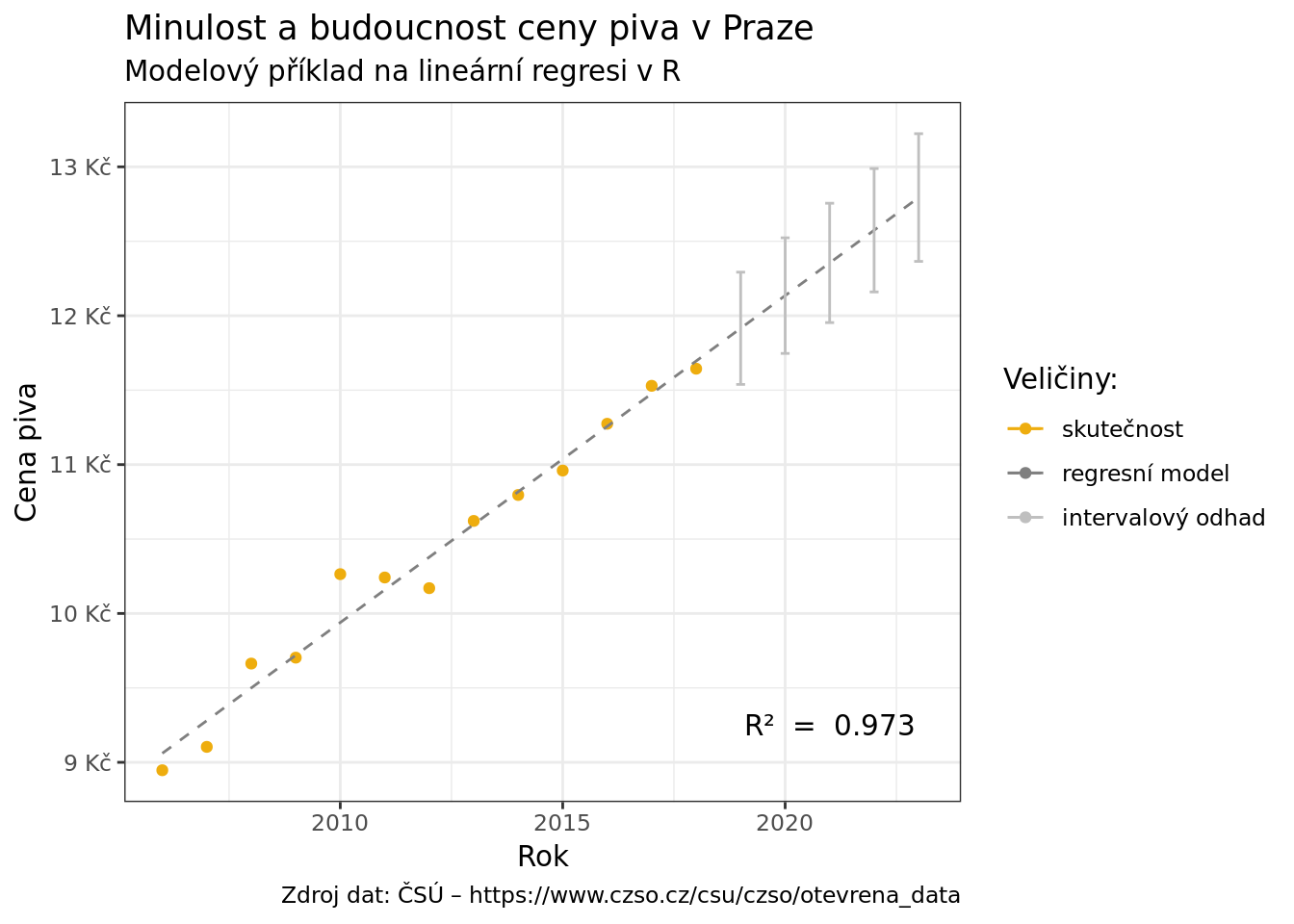
Vizualizace
Když jsme si vypočetli předpověď, tak o ní podáme zprávu.
Zvolili jsme složitější ggplot, který je postavený na třech zdrojích dat:
- skutečnosti (za roky 2006 – 2018)
- intervalové předpovědi (za roky 2019 – 2023)
- a prostém modelu (za celé období 2006 – 2023)
predpoved <- data.frame(rok = 2006:2023, # dataset předpovědi
cena = predict(model_piva, # model & nová data
newdata = data.frame(rok = 2006:2023)))
ggplot() + # bez dat a bez estetik - nejsou společné, ale 3x vlastní pro geomy
# první geom: skutečnost jako tečky v barvě piva
geom_point(data = pivo, aes(x = rok,
y = cena,
color = "darkgoldenrod2")) +
# druhý geom: čára modelu šedivě tečkovaně
geom_line(data = predpoved, aes(x = rok,
y = cena,
color = "gray50"), lty = 2) +
# třetí geom: 95% interval konfidence předpovědi světlejší šedivou
geom_errorbar(data = budoucnost, aes(x = 2019:2023,
ymin = lwr,
ymax = upr,
color = "gray75"),
width = .2) + # šířka čárek na konci
# popisky osy Y v českých korunách
scale_y_continuous(labels = scales::dollar_format(prefix = "",
suffix = " Kč")) +
# barvy - společné pro všechny 3 geomy
scale_color_identity(breaks = c("darkgoldenrod2", # barvy
"gray50",
"gray75"),
labels = c("skutečnost", # popisky legendy
"regresní model",
"intervalový odhad"),
guide = "legend") + # vynucení zobrazení
# popisky os, legendy, titulek grafu jako celku a zdroje pod čaruou
labs(title = "Minulost a budoucnost ceny piva v Praze",
subtitle = "Modelový příklad na lineární regresi v R",
caption = "Zdroj dat: ČSÚ – https://www.czso.cz/csu/czso/otevrena_data",
color = "Veličiny:",
x = "Rok",
y = "Cena piva") +
# anotace přímo do plochy grafu - vysvětlený rozptyl
annotate("text", x = 2021, y = 9.25,
label = paste("R² = ", round(summary(model_piva)$r.squared, 3))) +
theme_bw()