Když jsem začal projekt o twitterové komunikaci pravého a falešného Tomia Okamury, tak jsem zpracoval jejich timeliny od “počátku světa” do 7. prosince 2018.
Na těchto datech jsem vytvořil tři klasifikační modely, které různými technikami předvídaly “pravost” autora tweetu:
- rozhodovací strom nad tweetovými metadaty (
rpart) - jednoduchou neuronku nad stejnými metadaty (
keras, respektive TensorFlow) - sofistikovanější neuronku (bidirectional LSTM) nad slovy tweetů (opět
kerasa TensorFlow)
Zatímco jsem psal své klasifikační modely, tak Tomiové nezaháleli, a produkovali nová data. Od 7. prosince ke dnešnímu dni vydali 106 nových tweetů, z toho 51 od pravého a 55 od falešného Okamury. Což je vcelku vyvážené rozdělení, a v souladu s mým pozorováním, že fejkový Tomio je o něco ukecanější, nežli ten pravý.
Přišlo mi zajímavé použít nově vzniklé tweety jako verifikaci svých modelů, toto je můj výsledek:
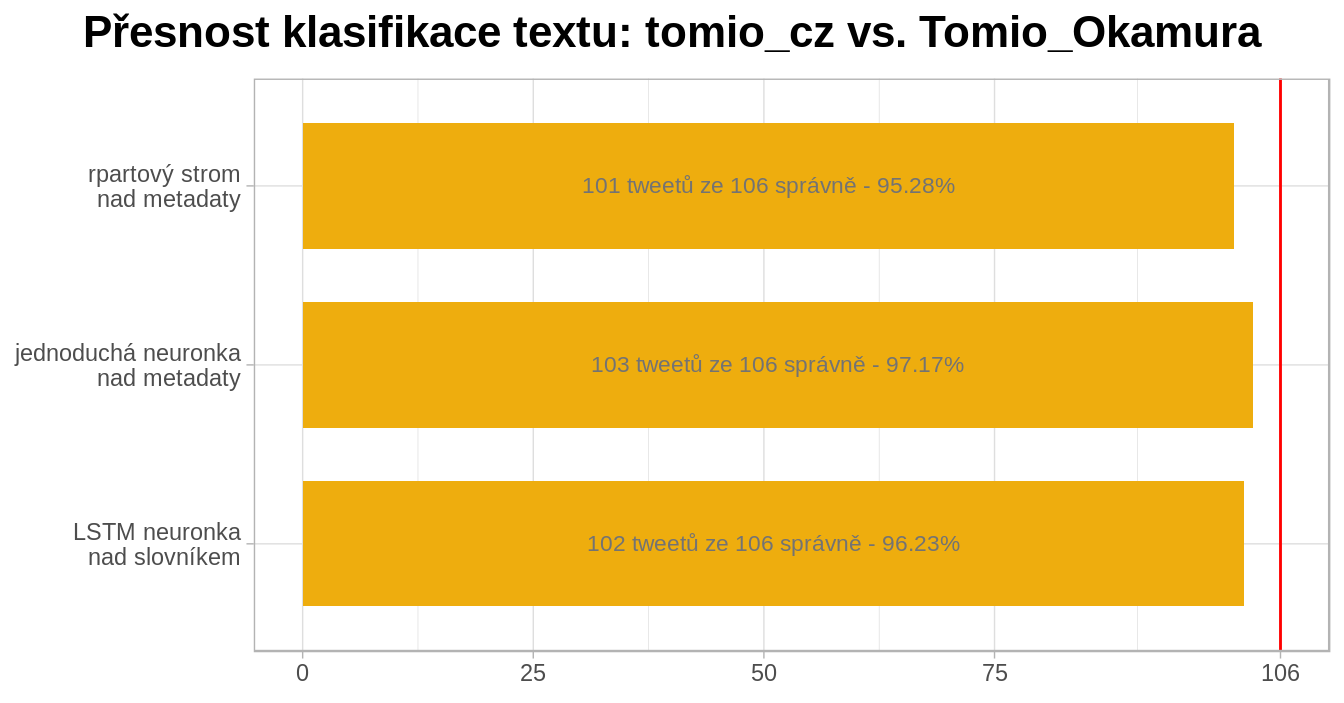
Testovací vzorek nebyl velký, ale i přes to dosahly všechny tři klasifikační modely přesnost přes 95%. Což není špatné…
Všechny tři výsledky jsou vcelku srovnatelné, a tak jsem se rozhodl za vítěze požadovat strom podle rpart. Protože jeho fungování dokážu ze všech tří metod nejsnáze vysvětlit.
Závěry, který si z projektu odnáším jsou že:
- klasifikace textu je zábavná, a jde dělat přesně
- Tomio Okamura je konzistentní a dobře předvídatelný
- i s malým Kašpárkem jde sehrát velké divadlo - respektive i jednoduchá technika se při dobré přípravě může výsledkem měřit s moderními AI krabičkami
Podkladové skripty jsou k dispozici na GitHubu: https://github.com/jlacko/dos-tomios.