Na českém Twitteru vystupují dva Tomiové Okamurové - jeden pravý, druhý falešný. Pro nás, lidi, nadané přirozenou inteligencí, není těžké už z profilovky na první dobrou poznat, který z nich k nám z jakého účtu promlouvá.

Přišlo mi ale zajímavé prozkoumat timeliny účtů @tomio_cz a @Tomio_Okamura strojově, technikami umělé inteligence.
A tedy změřit a spočítat jak oba Tomiové pracují s jazykem, a navrhnout takový klasifikační algoritmus, který by jejich tweety rozdělil na hejty xenofobního politika a hlášky internetového vtipálka.
Veškerou práci jsem provedl v erku - stažení dat přes knihovnu rtweet, textové zpracování přes knihovnu udpipe, a zpracování rozhodovacího stromu přes knihovnu rpart.
Prvotní stažení dat bylo jednoduché; obě timeliny mají dohromady přibližně 5 000 tweetů. Po rozbití na slova to dělá kolem 78 tisíc slov, to je rozsah zhruba čtyř diplomek (na VŠE klidně pěti). To už nějaká data jsou, ale stále dost málo na to aby se mi zafuněl notebook.
Dalším krokem bylo posoudit volbu slov oběma účty; protože se liší celkové počty tweetů (falešný Tomio je o něco ukecanější) nebylo praktické srovnávat absolutní hodnoty, a soustředil jsem se proto na srovnání relativních četností - zmínek slova na 1 000 tweetů.
Červená čára dělí čtverec četností na polovinu - napravo a dolů je více zmínek od pravého Tomia, nalevo a nahoru od falešného.
Postupně jsem zhodnotil hlavní slovní druhy:
- vlastní jména
- podstatná jména
- přídavná jména
- slovesa
- příslovce
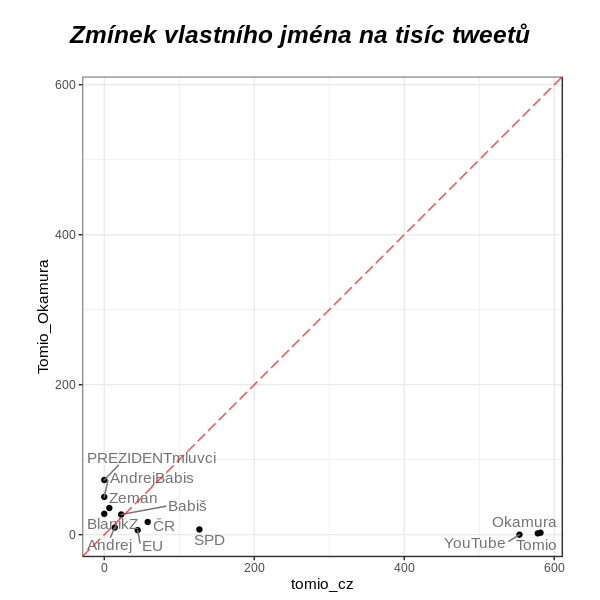
Je vidět, že pravý Tomio mluví hodně (hodně hodně!) o sobě a o SPD. Falešný Tomio mluví častěji než pravý o Ovčáčkovi, Zemanovi a Babišovi (a o Žížalovi, který mi mezi ty tři moc nezapadá).
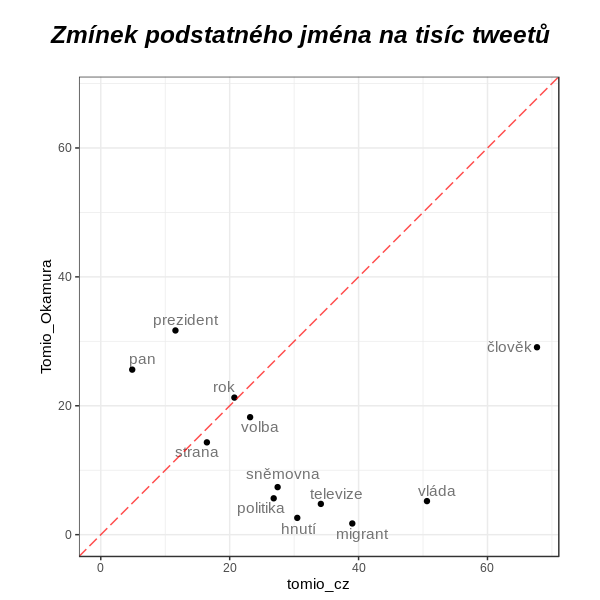
Z podstatných jmen mluví pravý Tomio hodně o člověku (o lidech), o vládě a o migrantech (které falešný Tomio ignoruje). Strana, volba a rok jsou důleživé pro oba Tomie srovnatelně, falešný se zajímá více o pana prezidenta.
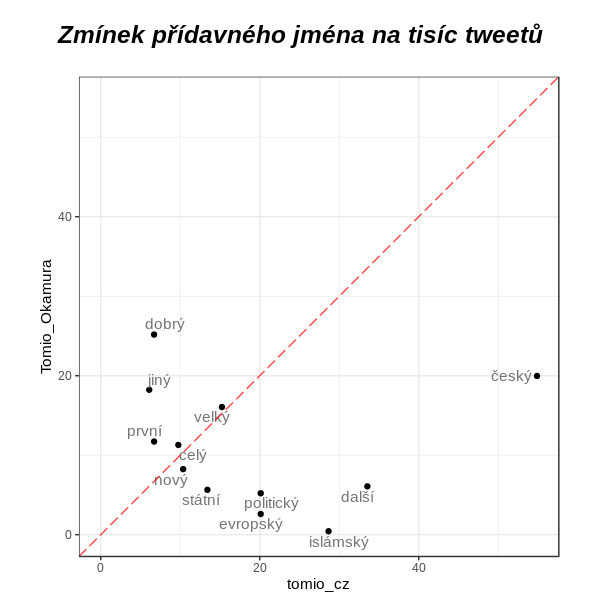
Z přídavných jmen je rozdíl v použití slov český, další a islámský; mimochodem - věděli jste, že pravý Tomio používá 4,26x častěji slovo islámský, nežli slovo dobrý?
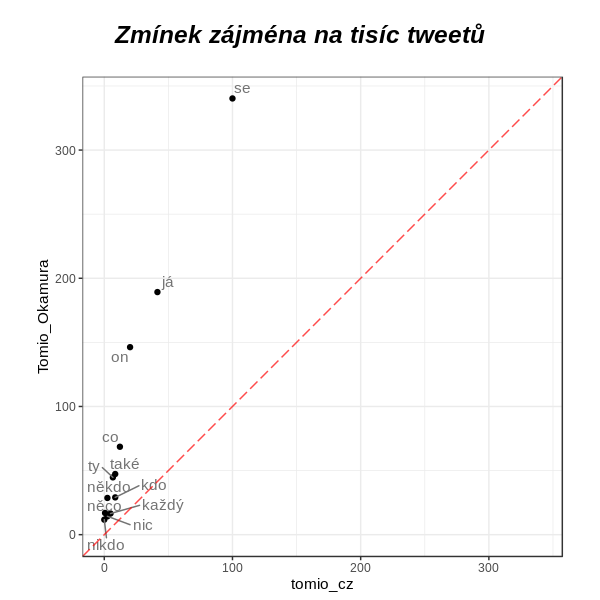
Na zájménech je nejzajímavější, že je pravý Tomio prakticky nepoužívá. Občas zmíní zvratné se, občas poukáže sám na sebe slovem já, ale ve srovnání s falešným Tomiem je to o ničem.
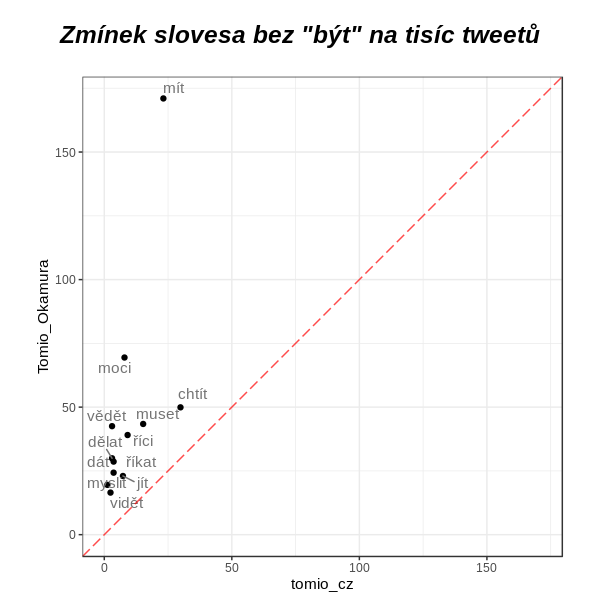
U sloves jsem musel, kvůli čitelnosti os, vypustit nejčastější být. I pro něj ale platí, že se slovesy je to jako se zájmeny - pravému Tomiovi prakticky vypadly, zatímco falešný Tomio s nimi pracuje.
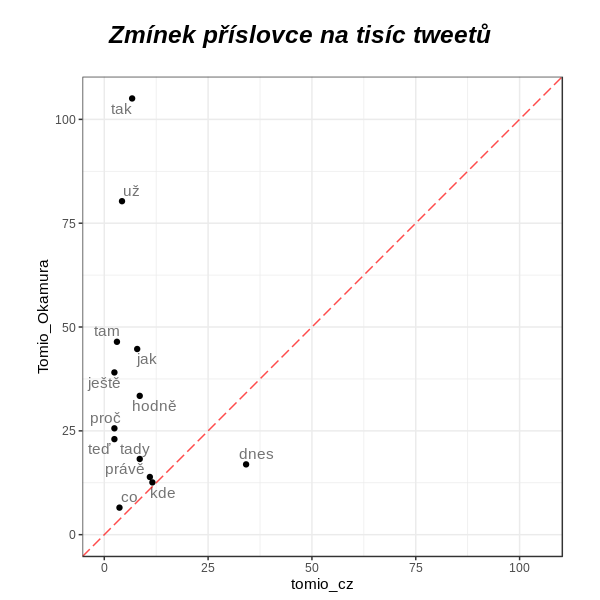
U příslovcí se příběh opakuje. S výjimkou jediného - úderného, naléhavost budícího dnes - jsou výsadou falešného Tomia.
Toto vše si vykládám tím, že pravý Tomio se nepotřebuje vyjadřovat ve skutečných větách. Jako populistický předák si vystačí s hesly. Na co podnět, k čemu přísudek - když soukmenovci trpí?
Falešný Tomio, který si z Tomia skutečného dělá legraci, nejspíše cítí potřebu se vyjadřovat jako člověk, a místo newspeaku používá češtinu.
Dalším krokem byla příprava dat pro klasifikaci. Na základě zjištění z analýzy jsem provedl lehký feature engineering - zaměříl jsem se na hlavní rozdíly, tedy odkazy na Youtube, sebepropagaci, použití sloves, zájmen a příslovcí a na sdílení cizích tweetů (retweety).
Výstupem z klasifikace je vcelku jednoduchý rozhodovací strom:
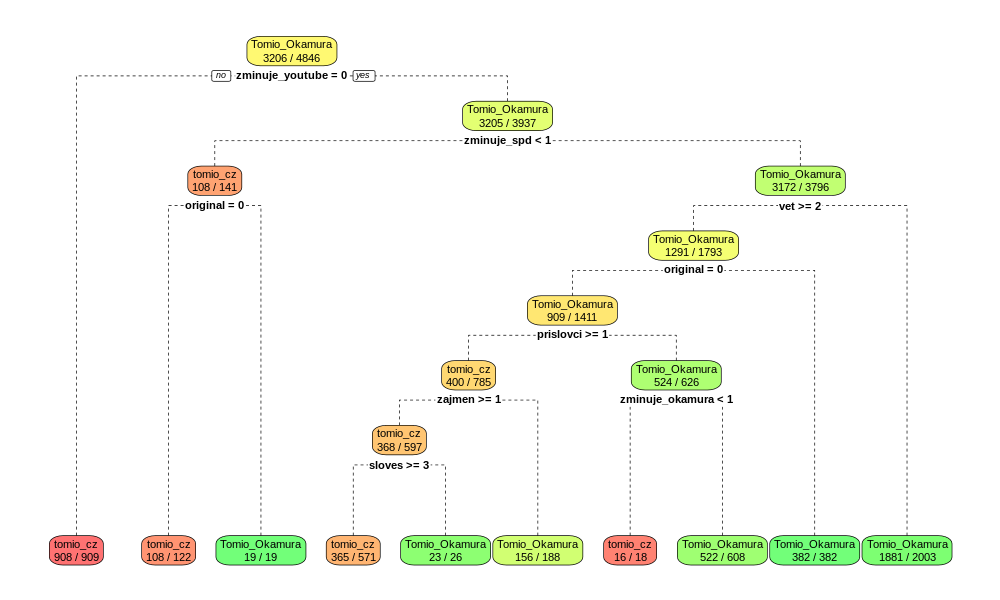
Strom má sedm úrovní, a dosahuje přesnosti klasifikace lehce přes 90%. Což je docela pěkné číslo.
S trochou nadsázky lze pravidla stromu ještě více zobecnit:
- příspěvek, který odkazuje na YouTube, je od pravého Tomia
- příspěvek, který zmiňuje SPD a není retweetem, je od pravého Tomia
- příspěvek o dvou a více větách je od falešného Tomia
- retweet je od falešného Tomia
- příspěvek, ze kterého vypadly zájména a příslovce, a který obsahuje maximálně dvě slovesa, je od pravého Tomia
Při stejném vstupním souboru s 30 proměnnými, ale se sofistikovanějším klasifikačním nástrojem - knihovnou Keras, respektive jejím backendem TensorFlow - se dostanu na úspěšnost kolem 92%. Pravda, hůře interpretovatelnou nežli jednoduchý rpartový strom.
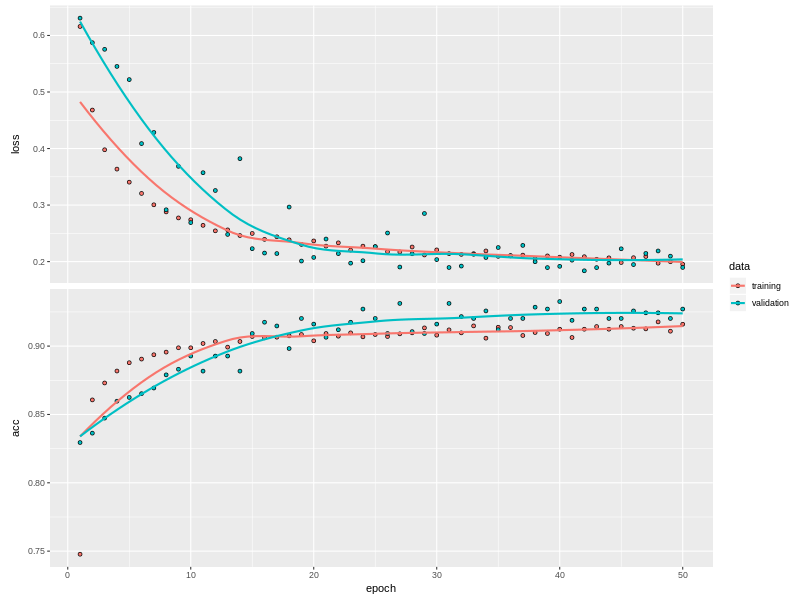
Věřím tedy, že při větším počtu proměnných a se složitějším feature engineeringem bych se dostal na úspěšnost kolem 95%, kterou mám za horní mez takhle “malého” souboru dat.
Zdrojový kód podkládající moji analýzu přesahuje rozsah blogového příspěvku, ale je volně k dispozici na GitHubovém repozitáři jlacko/dos-tomios.