Na CRANu se nedávno objevila package czso od Petra Bouchala. Tato package představuje interface z erka přímo do open datových struktur Českého statistického úřadu. S její pomocí snadno a rychle získáte čerstvá data, aniž byste přitom museli opustit pohodlí svého RStudia.
Prvním krokem pro orientaci je získání přehledu: k němu nám poslouží funkce czso_get_catalogue(), vracející seznam dostupných datových zdrojů, včetně základních metadat jako data.frame.
library(czso)
library(tidyverse) # kvůli dplyr & ggplot2
library(gganimate) # protože animace táhnou
# stahnu datový katalog / přehled dostupných sad
prehled <- czso::czso_get_catalogue()
# počet tabulek k dispozici
nrow(prehled)## [1] 605# přehled hlavních informací
prehled %>%
select(dataset_id,
title,
start,
end) %>%
head() # pro základní orientaci...## # A tibble: 6 x 4
## dataset_id title start end
## <chr> <chr> <date> <date>
## 1 060003 Vybavenost domácností informačními a komunik… 2007-01-01 2019-12-31
## 2 270229 Sklizeň zemědělských plodin podle krajů 2002-01-01 2019-12-31
## 3 110080 Průměrná hrubá měsíční mzda a medián mezd v … 2011-01-01 2018-12-31
## 4 270230 Hospodářská zvířata podle krajů 2002-01-01 2019-12-31
## 5 340130 Velikostní skupiny obcí 2001-01-01 2018-12-31
## 6 cis203 Číselník ČSÚ: Druh lesní dřeviny - agregace 1900-01-01 9999-09-09Druhým krokem bude získat konkrétní datovou sadu; k tomu potřebujeme znát její kód (najdeme jej v poli dataset_id). Zaměřím se na svoji oblíbenou datovou sadu ceny piva v čase; pivo je jedna ze základních potravin.
Dataset ceny základních potravin stáhnu pomocí funkce czso_get_table(), a základní přehled o konkrétní datové struktuře získám pomocí czso_get_table_schema().
# najdu ty zázamy z přehledu dat, které v poli "title" obsahují řetězec "potravin"
prehled %>%
filter(str_detect(title, "potravin")) %>%
select(dataset_id, title)## # A tibble: 1 x 2
## dataset_id title
## <chr> <chr>
## 1 012052 Průměrné spotřebitelské ceny vybraných výrobků - potravinářské výr…# zobrazím metadata (moc mi toho neřeknou, ale přece...)
czso::czso_get_table_schema("012052")## # A tibble: 11 x 5
## name titles `dc:description` required datatype
## <chr> <chr> <chr> <lgl> <chr>
## 1 idhod idhod unikátní identifikátor údaje Veřejné dat… TRUE string
## 2 hodnota hodnota zjištěná hodnota TRUE number
## 3 stapro_… stapro_… kód statistické proměnné ze systému SMS … TRUE string
## 4 reprcen… reprcen… číselník pro cenové reprezentanty TRUE string
## 5 reprcen… reprcen… kód z číselníku cenových reprezentantů TRUE string
## 6 obdobiod obdobiod referenční období počátek - ve formátu R… TRUE date
## 7 obdobido obdobido referenční období konec - ve formátu RRR… TRUE date
## 8 uzemi_c… uzemi_c… kód číselníku pro referenční území, číse… TRUE string
## 9 uzemi_k… uzemi_k… kód položky z číselníku pro referenční ú… TRUE string
## 10 uzemi_t… uzemi_t… text položky z číselníku pro referenční … TRUE string
## 11 reprcen… reprcen… text položky z číselníku pro cenové repr… TRUE string# načtu dataset základních potravin
potraviny <- czso::czso_get_table("012052")Když jsem dataset načetl, tak na něm provedu základní transformaci – vyberu položky pouze pro jednoho konkrétního cenového reprezentanta, zahodím krajský detail a transformuju text na datum.
Nad výsledkem pak mohu technikami {ggplot2}, respektive rozšiřujícího balíčku {gganimate}, postavit jednoduchou prezentaci vývoje ceny v čase.
# ze základních potravin vyberu tu nejzákladnější
pivo <- potraviny %>%
filter(reprcen_kod == "0213201") %>% # ... protože pivo :)
filter(uzemi_kod == "19") %>% # data za republiku jako celek (= ne kraje)
mutate(obdobiod = as.Date(obdobiod),
obdobido = as.Date(obdobido))
# a výsledek předložím graficky
ggplot(data = pivo, aes(x = obdobiod, y = hodnota)) +
geom_line(color = "red", size = 1.25) +
geom_point(color = "red", size = 2) +
labs(title = "Vývoj ceny piva v čase") +
scale_y_continuous(labels = scales::dollar_format(accuracy = .01, decimal.mark = ",",
prefix = "", suffix = " Kč")) +
scale_x_date(date_breaks = "1 year", date_labels = "%Y") +
theme_bw() +
theme(axis.title = element_blank()) +
gganimate::transition_reveal(obdobiod) # animační část...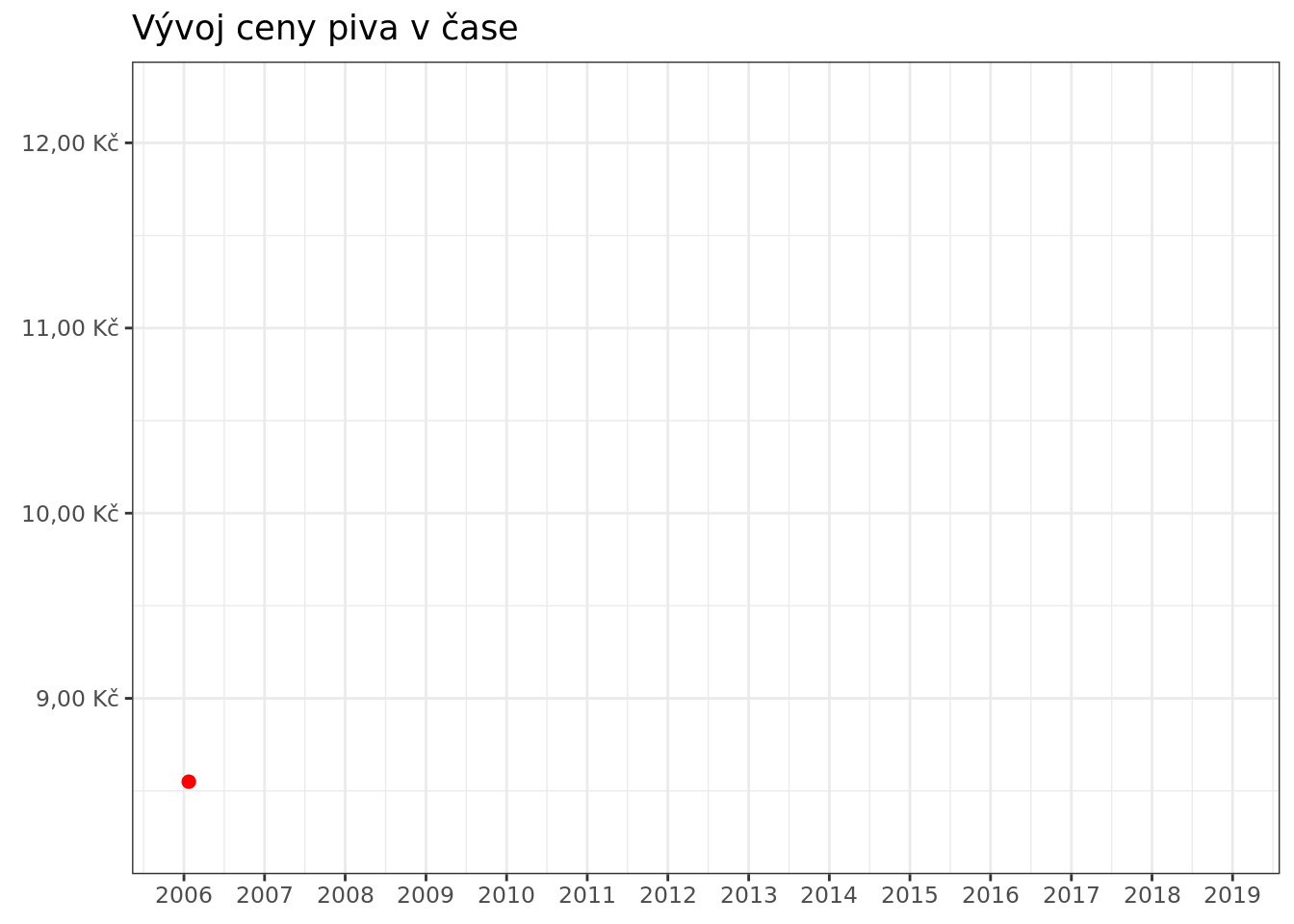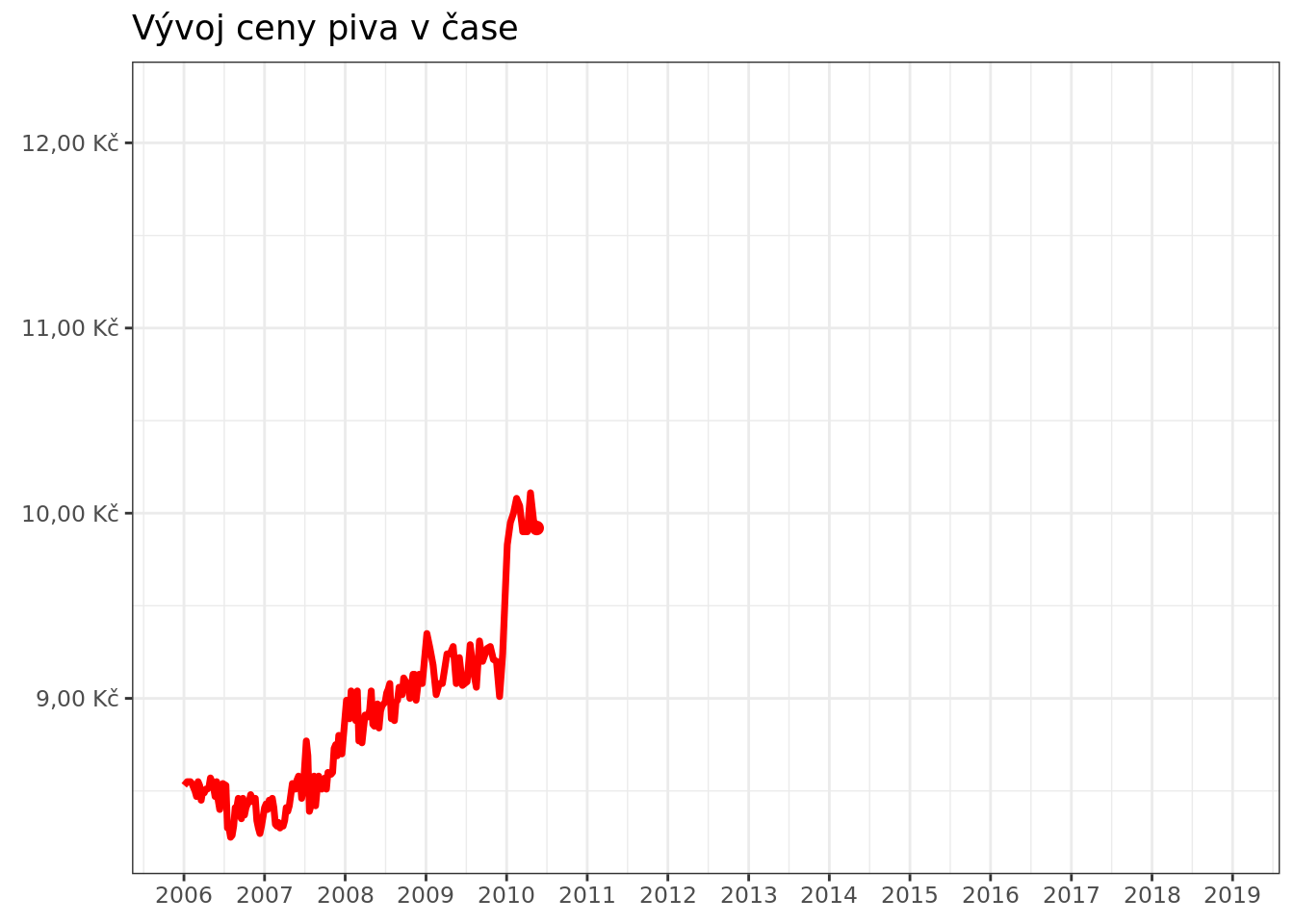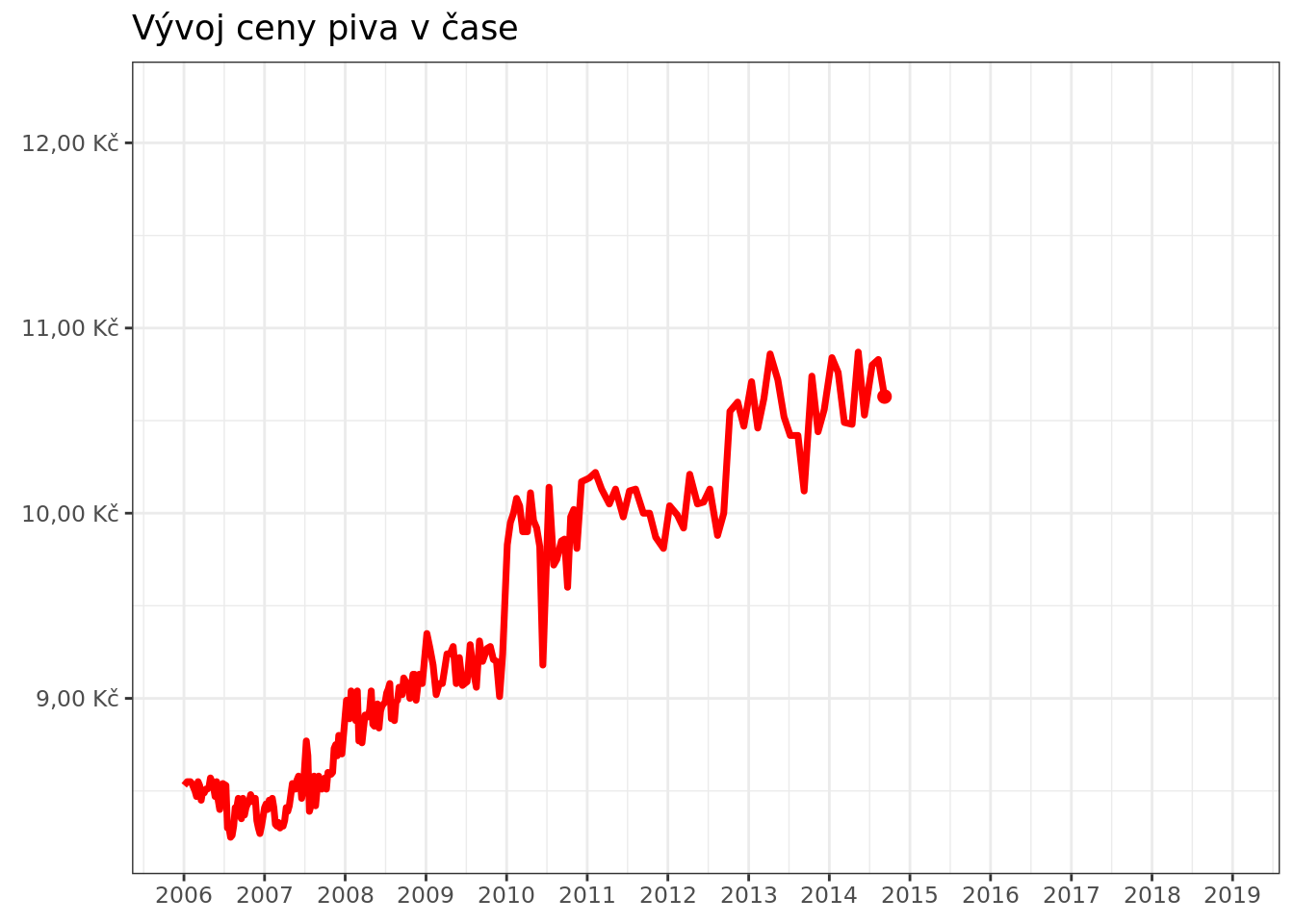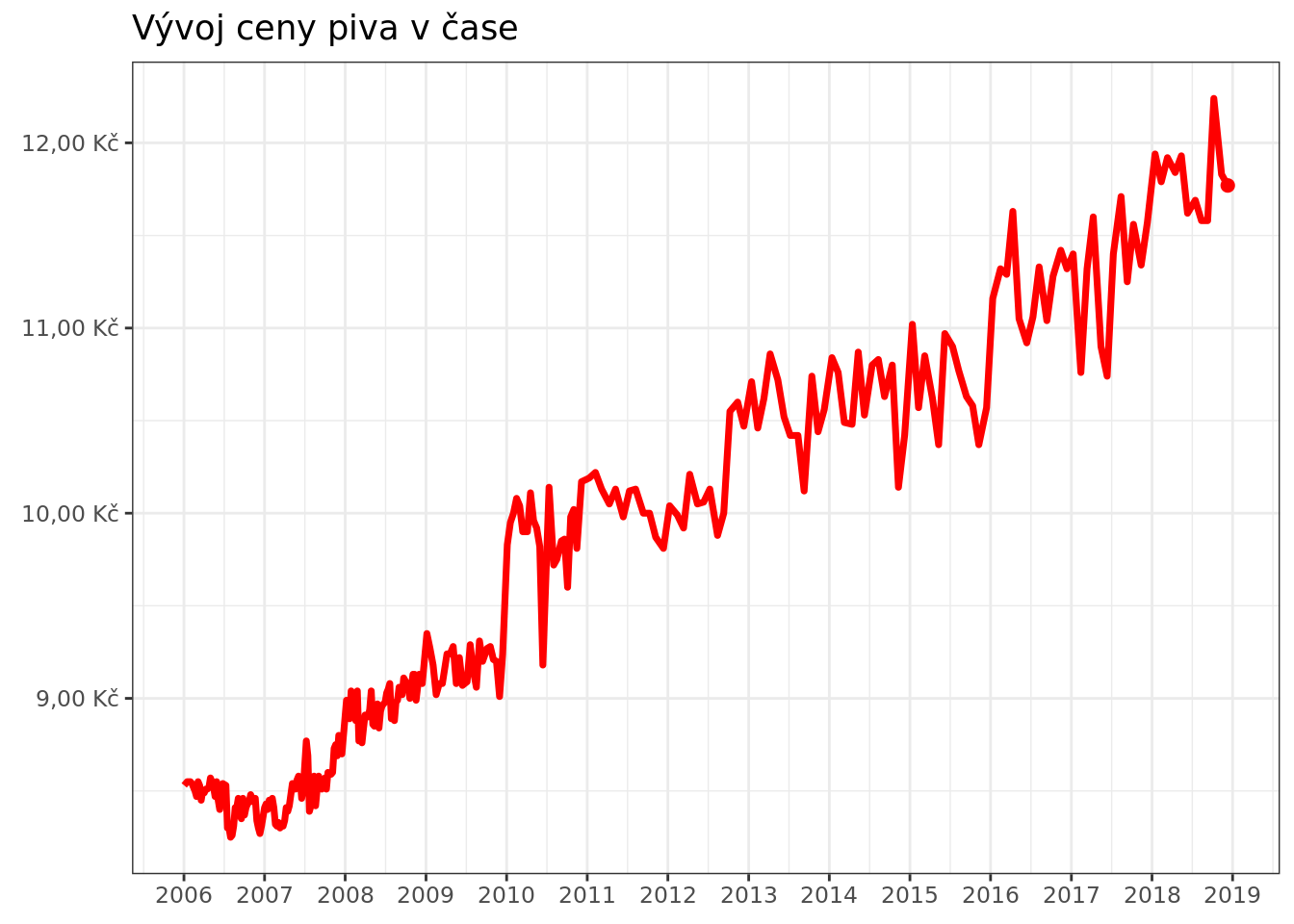
Příklad s pivem je (vědomě :) spíše lehčího žánru, ale věřím že jsem na něm předvedl jednoduchost a eleganci, s jakou lze čerpat data (a metadata) z otevřených dat ČSÚ přímo do běžícho erka.
Data jsou vždy čerstvá, a máme jistotu jejich kvality; nemusíme lovit pochybné excely někde po file systému.
Určitou nevýhodou této techniky je nutnost aktivního internetového připojení – jsem však přesvědčen, že výhody jasně převažují.