My všichni, kteří sledujeme vývoj nového koronaviru a politickou situaci v ČR, víme že:
… v březnu přišel někdo s matematickým modelem a v srpnu přišel ten samý člověk, ale ti, kteří měli přijít, tak ti už nepřišli …
Což mělo v obou případech zásadní dopad na chování strany a vlády.
V této souvislosti si mnozí z nás kladou otázku: jak složité je přijít s matematickým modelem?
Že to Řehák dokázal, a Dušek nikoliv?
Rád bych touto cestou (ne)složitost problému demonstroval na příkladě otevřených dat Ministerstva zdravotnictví, s využitím technik programovacího jazyka R.
Prvním krokem je aktivace knihovny {tidyverse} a načtení dat; erko podporuje načtení přímo z URL, tj. bez nutnosti ukládání mezivýsledku na disk. Hodnoty uložím do objektu ministerstvo.
library(tidyverse)
# načteme open data MZČR
ministerstvo <- read.csv(url("https://onemocneni-aktualne.mzcr.cz/api/v1/covid-19/nakaza.csv"))
# omezíme ke konci října (nová data jsou nový příběh)
ministerstvo <- ministerstvo %>%
filter(datum < as.Date('2020-11-01'))
# náhled na strukturu dat
glimpse(ministerstvo)## Rows: 279
## Columns: 3
## $ datum <chr> "2020-01-27", "2020-01-28", "2020-01-29", "2020-01-30", …
## $ pocet_den <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ pocet_celkem <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…Vidíme, ze v datech je datum jako textové pole; to není dobré ani pro modelování, ani pro vizualizaci.
Pro legendu grafů je žádoucí vyjádřit datum jako datový formát datum, pro vlastní výpočet je vhodné ho převézt na číslo.
Stanovím si proto číselnou pomocnou hodnotu den jako počet dní od konce prázdnin (den jedna bude 1. září).
Druhým krokem bude vlastní výpočet matematického modelu:
vím, že hledám exponenciálu, tedy funkci
pocet_den = a × (1 + r) ^ den, kdeaarjsou parametrypro nalezení hodnot obou parametrů použiji erkovou funkci
stats::nls()– zkratka od Nonlinear Least Squares, tj. odhad nelineárního modelu metodou nejmenších čtvercůmatematický model “nakrmím” vstupními hodnotami nakažených od 1. září do půlky října (použiju výběr hodnot z datového objektu
ministerstvo)abych urychlil hledání, tak modelu dodám jednoduché počáteční hodnoty obou parametrů
Abych udržel terminologii AB uložím natrénovaný model jako matematicky_model.
# malá transformace - datum jako datum, a den jako číslo
ministerstvo <- ministerstvo %>%
mutate(datum = as.Date(datum),
den = as.numeric(datum - as.Date("2020-08-31")))
# natrénujeme matematický model
matematicky_model <- nls(pocet_den ~ a * (1 + r)^(den),
data = subset(ministerstvo,
datum >= as.Date("2020-09-01") &
datum < as.Date("2020-10-15")),
start = list(a = 1, r = .01))
# shrnutí modelu - hodnoty parametrů, významnost &c.
summary(matematicky_model)##
## Formula: pocet_den ~ a * (1 + r)^(den)
##
## Parameters:
## Estimate Std. Error t value Pr(>|t|)
## a 4.716e+02 1.238e+02 3.808 0.000449 ***
## r 6.400e-02 7.474e-03 8.564 9.28e-11 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1115 on 42 degrees of freedom
##
## Number of iterations to convergence: 18
## Achieved convergence tolerance: 1.735e-06Není překvapivé, že takto jednoduchý model nemá problémy se statistickou významností.
Z připraveného matematického modelu si můžu spočítat čas ve dnech potřebný na zdvojnásobení počtu nakažených pacientů – je to podíl logaritmu dvojky a logaritmu (1 + r).
# čas ve dnech pro zdvojnásobení počtu nakažených
log(2) / log(1 + coef(matematicky_model)[["r"]])## [1] 11.1733Vychází mi tedy, že počet nově prokázaných výstkytů nákazy novým koronavirem v ČR má tendenci se zdvojnásobit jednou za 11 dní.
Třetím krokem pro mě bude predikce – na základě nalezeného matematického modelu si odhadnu hodnoty pro září, říjen a výhled na listopad (tedy celkem tři měsíce / 91 dní).
Hodnoty uložím, opět s přihlédnutím k slovníku AB, jako jiny_cas.
O výsledku podám zprávu graficky, technikou balíčku {ggplot2}.
# nové hodnoty - od září do listopadu 2020 jako vstup
jiny_cas <- data.frame(den = 0:91) %>%
mutate(datum = as.Date("2020-08-31") + den)
# predikce - uplatnění matematického modelu na nový vstup
jiny_cas$pocet_den <- predict(matematicky_model,
newdata = jiny_cas)
# grafické podání zprávy o skutečnosti a modelu
ggplot() +
geom_line(data = jiny_cas, aes(x = datum,
y = pocet_den),
color = "red") +
geom_point(data = ministerstvo, aes(x = datum,
y = pocet_den),
pch = 4, color = "gray50") +
scale_x_date(limits = c(as.Date("2020-08-31"), as.Date("2020-11-30"))) +
scale_y_continuous(labels = scales::number_format(big.mark = " ")) +
labs(title = "Počet nakažených COVID-19 v ČR",
subtitle = "matematický model & skutečnost") +
theme_minimal() +
theme(axis.title = element_blank())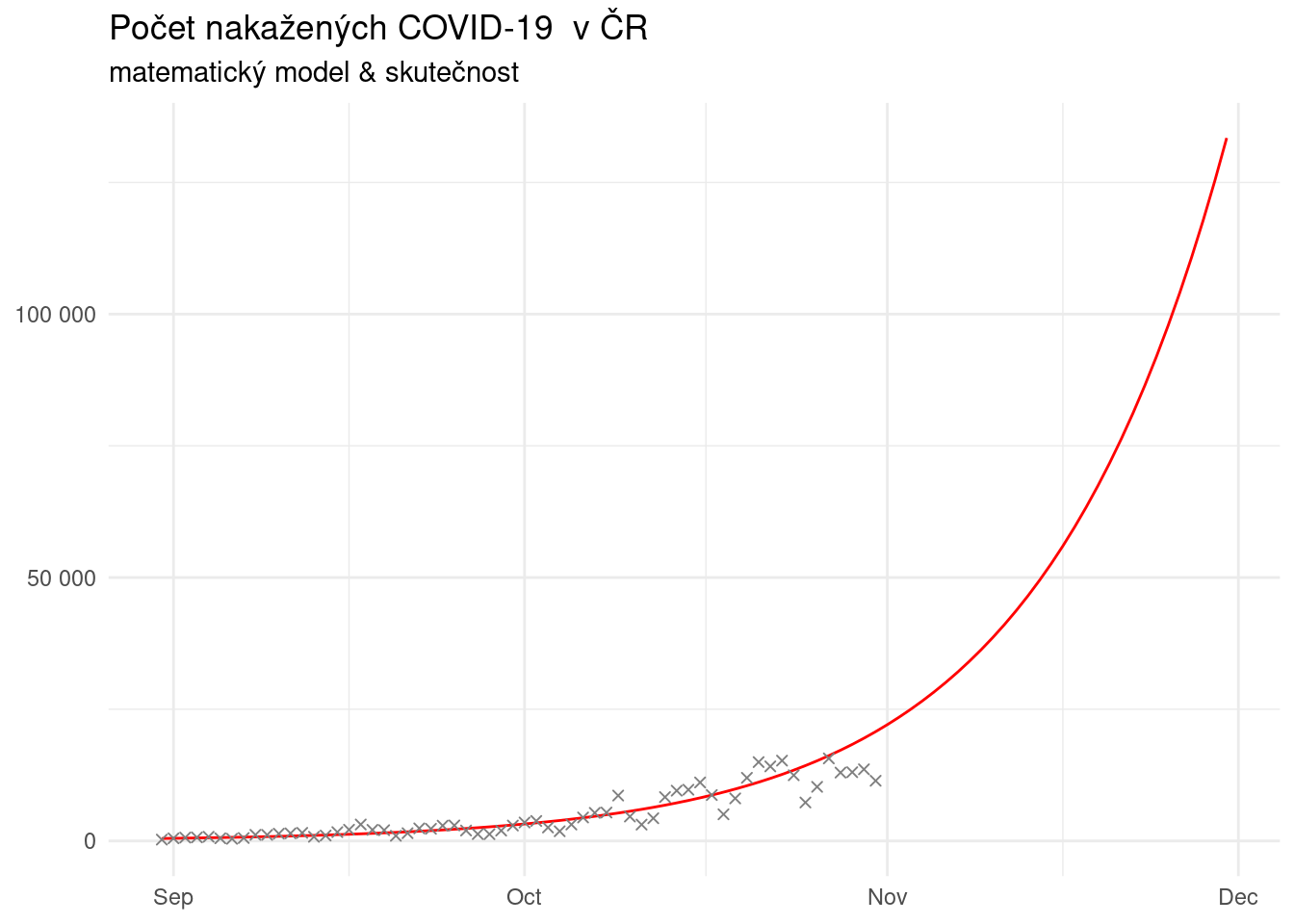
Závěr, který ze svého matematického modelu mohu udělat, je dvojí:
sestavit matematický model nákazy novým koronavirem z otevřených dat MZČR není raketová věda (dokázal to Řehák, dokázal jsem to já = dokážete to i vy!)
čeká nás zajímavý listopad, protože trend nelámeme = nad virem nevítězíme
Držím vám palce při zvládání COVID-19 i tvorbě matematických modelů; pokud v erku tak dvojnásob!